开云app登录 硬刚NVIDIA H100! 摩尔线程国产全新GPU初度公开: 单卡1千万亿次

智谱发布新一代大模子GLM-5之后,摩尔线程立即秘书,在旗舰级AI训推一体全功能GPU MTT S5000上完成了Day-0全经由适配与考证,第一时刻提供接济。
MTT S5000是摩尔线程专为大模子教训、推理及高性能沟通想象的全功能GPU智算卡,基于第四代MUSA架构“平湖”,原生适配PyTorch、Megatron-LM、vLLM、SGLang等主流框架。
它早在2024年就依然低调推出,然而具体造型、参数、性能一直莫得对外公开,十分机密。


此次在秘书适配GLM-5的同期,摩尔线程初度公布了MTT S5000的部分参数和性能,十分惊喜!
据悉,MTT S5000单卡配备多达80GB显存,显存带宽高达1.6TB/s,对比上代MTT S4000折柳提高了67%、113%,多卡间的互联带宽也有784GB/s。
它好意思满接济从FP8到FP64的全精度沟通,况且是国内最早原生接济FP8精度的教训GPU之一,确立了硬件级FP8 Tensor Core加快单位。
FP8比较BF16/FP16可将数据位宽减半、显存带宽压力缩小50%、表面沟通隐约量翻倍,并全面接济DeepSeek、Qwen等架构,教训性能可提高30%以上。
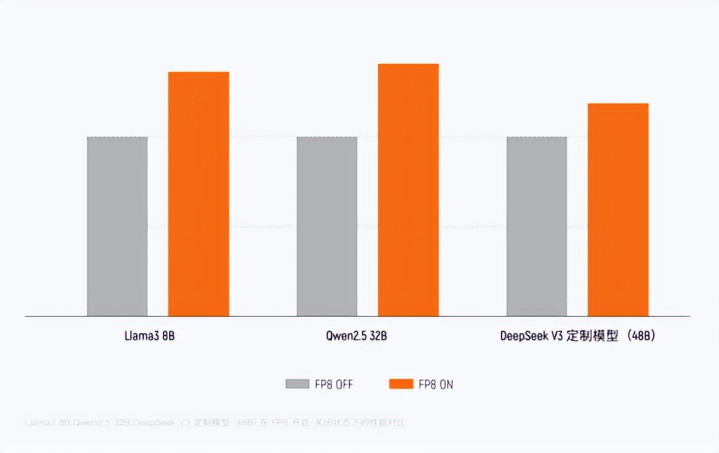
MTT S5000的单卡FP8 AI算力最高可达1000 TFLOPS,乐鱼初度达到PFLOPS级别,也便是每秒1千万亿次沟通。
比较之下,MTT S4000的算力为INT8 256 TOPS、BF16 128 TFLOPS、FP32/64 32/64 TFLOPS。
据业内东说念主士称,MTT S5000实测性能不错对标NVIDIA H100,尤其是在多模态大模子微调任务中,部分性能更是特出H100,致使启动接近最新的Blackwell架构。
2026年1月,智源量度院基于MTT S5000千卡集群,开云app完成了前沿具身大脑模子RoboBrain 2.5(数千亿参数)的端到端教训与对都考证,MTT S5000进展出了与H100集群极高的律例一致性,练耗费值(loss)各别仅为0.62%,合座教训成果致使杀青小幅特出。
另据互联网厂商的场景实测,MTT S5000在典型端到端推理及教训任务中,性能不错达到NVIDIA H20的2.5倍左右。
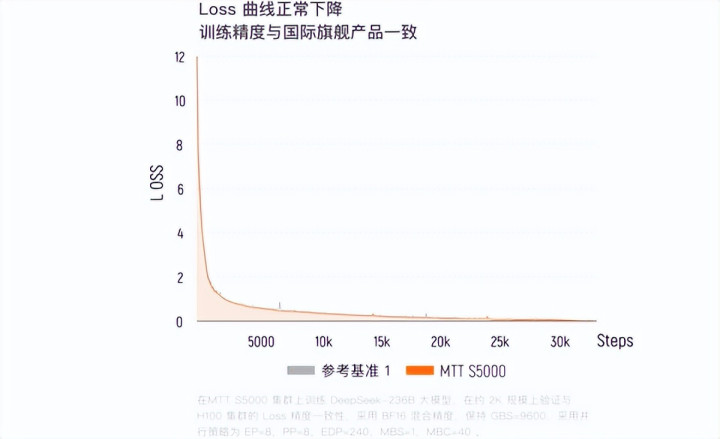
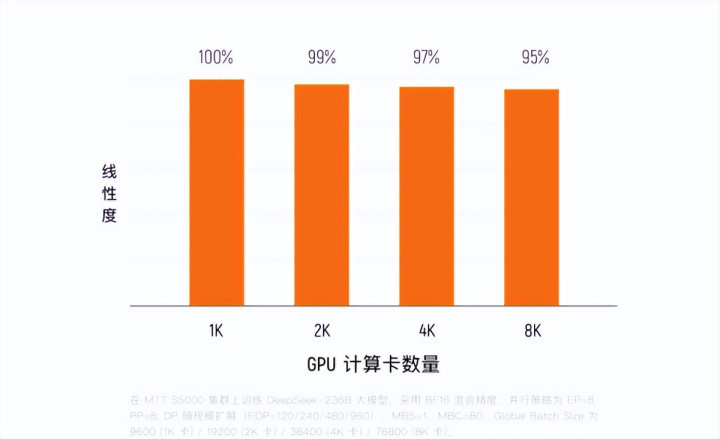
当今,基于MTT S5000的夸娥万卡集群依然落地,浮点运算才气达到10Flops(每秒1千亿亿次沟通),在Dense繁密模子教训中MFU达到60%,在MoE大师模子中防守在40%左右,灵验教训时刻占比越过90%,教训线性扩张效劳达95%。
{jz:field.toptypename/}基于原生FP8才气,它能好意思满复现顶尖大模子的教训经由,Flash Attention算力诓骗率越过95%,多项要津磋议均达到海外主活水平。
值得一提的是,MTT S5000在集群通讯层面弃取开创的ACE手艺,将复杂通讯任务从沟通中枢卸载,大幅提高模子算力诓骗率(MFU)。
实测流露,MTT S5000从64卡扩张至1024卡,系统的线性扩张效劳保捏在90%以上,教训速率随算力增多确凿同步倍增。

MTT S5000在推理场景相似进展优异,比如在2025年12月,摩尔线程说合硅基流动基于MTT S5000完成了对DeepSeek-V3 671B满血版的深度适配与性能测试。
实测单卡Prefill隐约越过4000 tokens/s,Decode隐约越过1000 tokens/s,刷新了国产GPU的推理记录。

 备案号:
备案号: